Predict the NBA with Machine Learning Methods
最近在复习机器学习的模型,心血来潮想找点数据跑一跑。刚好看到这篇文章,里面使用机器学习模型去预测 NBA 比赛的结果。一个是挺好玩,自己对篮球也比较熟悉;另一个是 NBA 的数据统计非常齐全,比赛的结果和数据统计也存在一定的关系,直觉上应该适合使用机器学习进行预测。因此自己准备爬爬数据玩一玩。
开始动手之前的第一步是整体分析,主要目标是预测 NBA 比赛结果,要先确定什么因素会影响一场 NBA 比赛的结果。首先能想到的几点:
- 球队赛季的比赛净胜分
- 球队赛季的胜率(战绩)
- 主客场因素
- 双方战术运用
- 球员之间的配合情况
- 其他场外因素
其中后三点是比较难以通过现有的数据统计直接反映出来,或者比较难以量化的,因此这里主要关注前三点。在前三点基础上初步确定下面 8 个特征:
- 主/客队过去所有比赛的胜率
- 主/客队过去所有比赛的净胜分
- 主队在主场的胜率,客队在客场的胜率
- 主队在主场的净胜分,客队在客场的净胜分
Data
第二步是爬取需要的数据。basketball-reference 是一个专业的篮球数据网站,涵盖了各式各样篮球统计数据,详细比赛数据、球员基本/高阶数据、球队基本/高阶数据,每个球员每场比赛每个投篮的位置、投篮距离等等。网站上大部分数据都可以通过直接爬取静态 html 页面获取,没有太多复杂的反爬虫机制。可以使用 Python 的 BeautifulSoup 库解析 HTML 页面获取所需数据。比赛赛程安排及结果示意图如下:
先爬取 07-08 赛季到 16-17 赛季总共 10 个赛季的的 NBA 的比赛数据统计,包括日期、主客队、比分、比赛类型(常规赛或季后赛),比赛场次统计如下
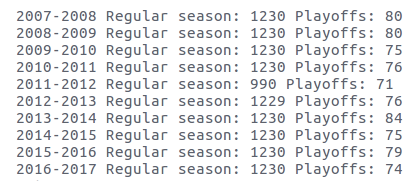
每个赛季每支球队打 82 场常规赛,总共 30 支球队,共计 1230 场次。11-12 赛季由于联盟停摆每支球队只打了 66 场常规赛,共计 990 场次。12-13 赛季由于 13 年 4 月美国发生波士顿爆炸案,导致凯尔特人主场和步行者的一场比赛被取消了,比其他正常赛季少了 1 场常规赛。
本文只预测常规赛的比赛结果,10 个赛季总共有 12059 场常规赛。接着从这 12059 场比赛中构建前文提到的八个特征。 我们先取一个赛季的数据来构造特征,由于有一部分特征需要前 10 场比赛的数据,对于赛季开始的前 10 场,我们使用上赛季末的比赛进行补齐。每场比赛对应一个 8 维的特征,label 表示主队获胜与否。下图为某三场比赛特征和标签格式(未归一化):

NOTE: 在 10 个赛季中先后有 4 支球队更换了队名,需要对队名更换进行处理。
Prediction
有了处理好的数据集之后,接下来的流程就比较规范了。首先对 12059 条数据进行随机划分训练集和测试集(训练集 80%,测试集 20%)。机器学习库采用 Scikit Learn,分别在训练集上尝试 Logistic Regression、SVM(linear/kernel)、Random Forest、神经网络几种模型作为分类模型训练,模型超参的调优方面用 Random search 搜索较优的超参数配置。
各组模型在各个赛季的训练集和测试集上的最佳准确率如下表。

从上表可以看到所有模型中 LR 模型的性能最佳,达到 69.11%的预测准确率。几种模型的性能相差很小,说明 69%这条线基本上就是采用当前特征的性能上限了,想要再提高预测准确率,必须在特征上下功夫(当前使用的特征只是局限地考虑球队近期/赛季的胜率、净胜分等,实际上影响比赛结果的因素远不止这些)。
这个结果并不算理想,我们的目标是能够拿到这个模型去买球不亏钱。考虑引入其他的特征来提升模型性能。我尝试了国外博彩网站赛前对每场比赛两支球队的赔率作为特征,理论上这应该是一个比较“强力”的特征,因为博彩网站往往掌握了很多一般人不知道的场内场外信息,这个赔率包含了更多与比赛相关的信息,应该对模型的预测有所提升。
赔率数据来源于这里,是 Excel 格式的文件,只需要用 python 提取所需信息即可。我们先简单看看这个赔率的预测准确性(赔率高的一方为赢,低的一方为输),可以看到单单用这种简单的判定就能够打达到 64%的准确率,可见这个特征是比较有用的。用加入新特征的数据重新训练模型,结果如下。
IMG HERE
可以看到,各个模型的预测准确率都有所提升,最佳的 LR 能达到 70%左右的准确率。
Player Clustering
TODO
Others
TODO
一点感想
小小回顾一下,整个过程大概 80%的时间是在处理数据(爬取、清理、提取等),不过因为这些数据本身还蛮感兴趣的,所以倒也没有觉得很烦,并且 basketball-reference 没有太多的反爬虫机制(谢天谢地)。
然后又一次验证了机器学习中一个真理: 数据(特征)决定了性能的上限,不同的算法只是以不同的方式去逼近这个上限而已。实际应用中对数据的深刻理解是非常非常重要的,理解业务领域背景、数据与业务的联系、数据间的关系,才能构造更 valuable 的特征。也算是一点小小的收获吧。(当然 Deep Neural Nets 可以在一定程度上降低特征工程的工作量,但一个前提是数据要足够充足,在这篇 post 讨论的这个问题场景下,数据量并不充足)