Deep Learning Book Reading Notes
Abstract
Deep Learning Book零碎读书笔记。
Chap4 数值计算
数值上溢和下溢
深度学习涉及大量的数值计算,使用一定数位表示的数字带来的溢出可能使深度学习出现问题。(大量的连续计算会使误差不断累积)
- 下溢:很小的正数被表示为 0(除于零的错误)
- 上溢:超过数位能表示的上界,可能被表示成一个非数字的值
需要特别注意常用的函数 softmax:
- 当所有 x 是非常大的负数时, \(\exp(x)\) 可能发生下溢,导致分母为 0,结果未定义;
- 当所有 x 是非常大的正数时, \(\exp(x)\) 可能发生上溢,结果同样未定义;
通常的处理是:所有 x 都减去 max(x),可以防止溢出,同时保持 softmax 结果不变,即:
Jacobian and Hessian Matrices
一阶(Jacobian)和二阶(Hessian)导数在输入和输出均为多维变量时候的推广。
Jacobian 可以用来计算 critical point,即导数为 0 的点,而 Hessian 可以用来判断临界点是不是最值。当 Hessian 矩阵所有特征值均为正时,该临界点是局部最小值;反之特征值均为负时,临界点是局部最大值。 如果只使用梯度信息的优化算法成为一阶优化算法(梯度下降),使用 Hessian 矩阵信息的优化算法称为二阶优化算法(牛顿法)。
Intuitive 的理解: 梯度下降每次找坡度最大的方向走,牛顿法则不仅考虑坡度的大小,还考虑走了一步后坡度是否会变大 </u>。
Chap5 机器学习
基本的概念
定义:对于某个 Task,有特定的 Performance Measure 和一定数量的 Experience,使用机器学习算法从 Experience 中学习数据的特征,从而达到比较高的 Performance。
模型容量/过拟合/欠拟合
ML 中一个关键的问题就是模型的泛化能力(未知数据的表现)。需平衡两个目标: Training error 尽量小 和 Training error 和 T est error 的差距尽量小。
-
Model capacity
过拟合和欠拟合的一个关键因素就是模型的 capacity 控制 capacity 的一个方法就是选择模型的假设空间 hypothesis space(线性、多项式等),最好的情况是 模型的 capacity 和 task 真实的复杂度相近 。
-
VC 维
VC 维是衡量二分类模型 capacity 的一项指标。VC 维 = d,表明模型的假设空间的函数能对最多 d 个数据进行任意的二分类。
-
learning theory 一个重要的结论:
Training error 和 Test error 的差距存在上限 b(置信风险),置信风险 b 随着模型复杂度增加而变大,随着训练数据增多而变小。
$$ R(\alpha)\leq R_{emp}(\alpha)+\sqrt{\frac{h(\log(\frac{2m}{h}+1))-\log(\frac{\eta}{4})}{m}} $$ -
Regularization
Regularization 是一项用于帮助算法降低 Test error 而不是 Training error 的技术。(L1/L2, Dropout, weight decay, etc.)
-
Hyperpatameters
关于 hyperparameter 的选择,通常不使用 trainingset 来选择 hyperparamaters,而是通过额外的 validation set 来选择好的超参数。
通常的做法是从训练集中分一小部分出来作为验证集,训练集用于训练模型参数,验证集用于训练超参数。 如果总数据量少,可以采用交叉验证,通过多次不同的划分训练集/验证集/测试集,最后平均结果。
Bias 和 Variance
Estimator 即对参数的估计,Bias 和 Variance 是一个 Estimator 里面两种不同的 error。
-
Bias
Bias 表示估计的参数与真实参数之间的偏差 ,一个模型 Bias=0 即称为是 unbiased 的,即估计参数的期望等于真实参数;还有一个概念是渐进 unbiased,表示当训练数据 m 无穷大时估计参数的期望等于真实参数。 Bias 很大是通常表示 Underfitting,即估计的模型与实际的模型相差很多
-
variance
Variance 则表示 对于同一个 estimator,多次不同的 sample 得到的结果的方差 ,可以看作是泛化能力。 Variance 很大通常表示 Overfitting,即估计的参数在训练集上的结果与在测试集上的结果相差很多,泛化能力差。
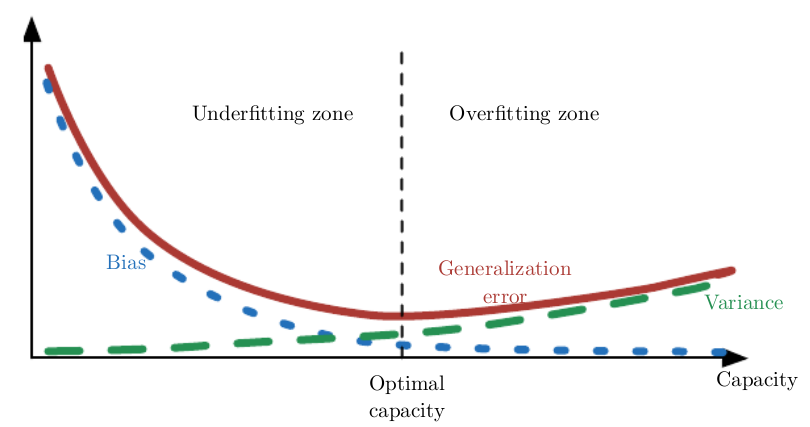
上图中横轴是模型容量,纵轴是 error 大小,其中 Generalization error = Bias + Variance。
- 模型容量较小时,Bias 大,underfitting;
- 模型容量适中时,Bias 和 Variance 都比较小,Generalization error 也比较小;此时的模型容量最佳;
- 模型容量大于实际问题复杂度时;Bias 继续减小,但是 Variance 开始上升,开始 overfitting;
极大似然估计
极大似然估计可以看作是最小化估计的分布 p_model 和数据真实分布 p_data 之间的距离(让模型分布与真实分布尽量相似) 衡量两个分布之间的距离采用 KL 散度,即极大似然估计可以看作最小化 KL 散度。
上式第一项由训练数据决定,因此我们要改变模型最小化 KL 散度,只需关注第二项(与模型相关)。实际上第二项就是我们常用的交叉熵。
监督学习 / SVM / k 近邻 / 决策树
- SVM:详细 SVM 模型推导参考这里
-
K-NN:Non-probabilitic supervised algorithm,可用于分类或回归
k-NN 其实属于无参数的模型,可以看作是生成关于训练数据的一个函数。 当训练数据很大的时候,可以看作模型的 capacity 很大,但是 K-NN 的 compute cost 也很大
传统机器学习算法局限(why deep learning)
- 维数灾难——传统机器学习算法难以处理高维度的数据。
- 局部稳定性——稍微改变模型输入时,模型的输出也应该是发生微小改变,而不是剧变。
Chap6 Deep Neural Nets
-
Output Unit
线性输出(回归),sigmoid 输出(二分类),softmax 输出(多分类)
-
Hidden Unit
-
ReLU (当 x=0 时不可导,但是这样情况在真实应用中可以忽略不计(参数中的 b 通常初始化为很小的正数保证这个 ReLU 能被激活。几种 ReLu 的变种:
$$ h_i=g(z_i, \alpha) = \max(0,z_i)+\alpha_i\min(0,z_i) $$- Absolute value rectification 将上式的 alpha 固定为-1,相当于将线性输出转变为其绝对值
- Leaky rextification 将上式的 alpha 设为很小的正数(0.01),相当于给负数一个很小的梯度
- Parametric rectification 将上式的 alpha 当作一个可训练的参数
-
sigmoid 和 tanh
现在比较少用于隐层激活,因为容易导致梯度消失的问题(梯度在非常大的正数或非常小的负数时变得很小
- 一些不太常用的 softplus / Hard tanh / softmax
-
-
Universal Approximation Theorem 一个(带激活函数的)多层感知机有能力 represent 任意函数(但是不保证能通过训练得到这样的 represent)。 实践角度,使用深层网络能够达到更好的效果(虽然相比浅层网络更难训练)
Chap7 Regularization
-
L1/L2
L1 往往会导致参数变得稀疏,因此也有使用 L1 作特征选择的做法;而 L2 则相对更加平滑(集体变小)。intuition 如下图

其中蓝色圆圈表示假设空间,正方形和圆分别是了 L1 和 L2 限制,相切点为解,可以看到 L1 中大部分解都在四个交叉点(一个参数为 0),而 L2 则大部分解 (W1, W2) 都有值(W1,W2 都变小)
-
Data Augmentation
- 对于分类任务,可以对训练数据进行一定的转化创造更多的‘假数据’,增加了训练数据的数量,能够训练得到泛化能力更强的模型
- 对输入或者中间层的输入注入 finetuned 的噪声可以在一定程度上提高模型的鲁棒性(Dropout 可以看作是对隐层注入噪声
-
Multi-Task learning
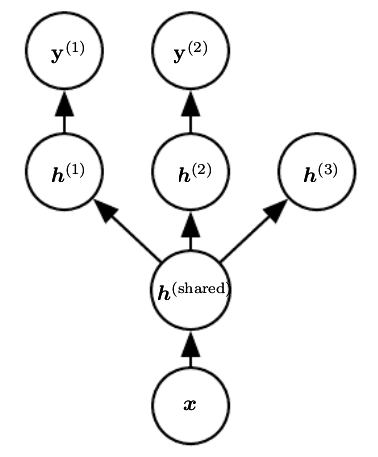
上图为常见的 multi-task leanring 的结构,其中 \(h^{share}\) 是多个 task 共享的 representation,上层的 \(h^{k}\) 是 task-specified 的。
multi-task leanring 强迫学习多个 task 之间共通的 representation,可以提高模型的泛化能力。
-
Early-stop
一个模型随着训练的进行,Training error 会不断降低,但是 Test error 可能会先降低而后又升高。
Early-stop 的思路是:在训练的过程中每隔一段时间计算 test error,如果 test error 有改善,则保存模型参数;如果超过足够大的时间(或者足够多的步数)test error 都没有改善,则停止训练,取 performance 最好的模型参数作为结果;
early-stop 其实可以看作是通过控制训练(拟合训练数据)的步数来控制模型的 capacity,是常用的 regularization 技术。
Chap9 CNN
- 基本
- 结构:
INPUT -> [[CONV->ReLU]*n (->POOL)]*m -> [FC->RELU]*k -> FC -> OUTPUT - 适用于处理网格结构数据(sequence data 一维网格,image 二维网格)
- CNN 和全连接的差别就是层与层之间的矩阵乘法变成了卷积操作;
- 一层卷积操作可以看作是由多个可学习的滤波器对圆图像进行滤波,滤波器高度和宽度通常比原图小,深度和原图一样。每个滤波器可以看作是对应一个特征(边缘等);
- 结构:
- Pooling
- 常见的 pooling 有 max 和 average (max pooling 效果更好)
- 通常是在连续的卷积后周期地插入 pooling(逐渐降低参数的数量)(pooling size 太大会对网络造成伤害)
- 现在部分 CNN 倾向于使用递增的 stride 来取代 pooling(也可以降低参数数量)
- 卷积层的超参:#filters, filter_size, stride, zero-padding
- 实践
- 通常 pooling 使用 max
- 通常更倾向于多个小的 filter 层叠而不是一个大的 filter
- 通常 CNN 中卷积层参数相比 FC 要少得多,但是卷积操作会占据大量的计算和内存资源
Chap10 RNN
-
基本原理
RNN 处理序列数据(序列输入,序列输出),RNN 基本原理就是内部维护一个可以表示历史信息的状态,每个 timestep 的计算不仅考虑当前的输入,还考虑上个时刻的 hiddent state(历史信息
-
主要问题
long time dependencies(从而导致梯度弥散)
- DNN 的局限
- DNN 假设训练数据之间是独立的,并且通常情况下要求输入是固定长度的,对于变长的、具有时间依赖性的数据难以处理
- 通过在 DNN 的输入加输入前几个时刻的信息可以在一定程度上解决时间依赖性的问题,但是不是最佳方法(无法解决长期依赖
- 权值共享
- CNN 包含权值共享的思想,当使用 CNN 处理 1 维数据的时候,也可以在一定程度上解决前后依赖的问题(滑动的权值窗口(每次的输出是一个窗口的函数
- RNN 则是和 CNN 不同的权值共享的思路,每次的输出是前面的包含前面信息的 hidden state 的函数
- 梯度弥散和梯度爆炸问题
- 因为 RNN 只有一套参数,因此在多个 timestep 上 BP 会使参数 w 连乘,如果
w > 1,则梯度爆炸,如果w < 1则梯度弥散 - 普通的全连接网络因为每层的 w 都不同,所以连乘并不容易出现弥散的情况。(出现弥散的原因可能是采用了 sigmoid 或 tanh 作为激活函数
- 梯度爆炸使用 clip gradient 解决,梯度弥散使用 LSTM
- 因为 RNN 只有一套参数,因此在多个 timestep 上 BP 会使参数 w 连乘,如果
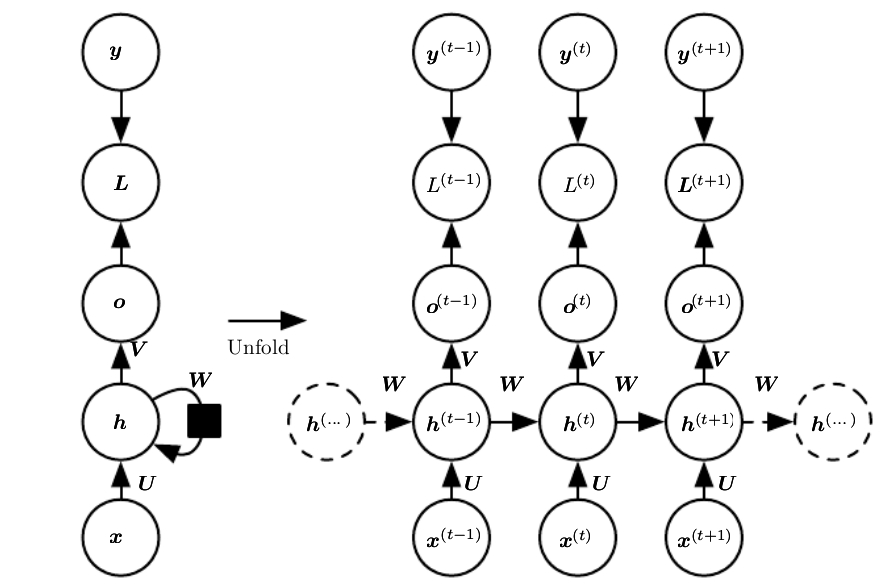
- RNN 经典结构 每个时刻输出 output,并且在不同 time step 的 hidden state 间有循环的连接(一般 RNN 指的就是这种结构)
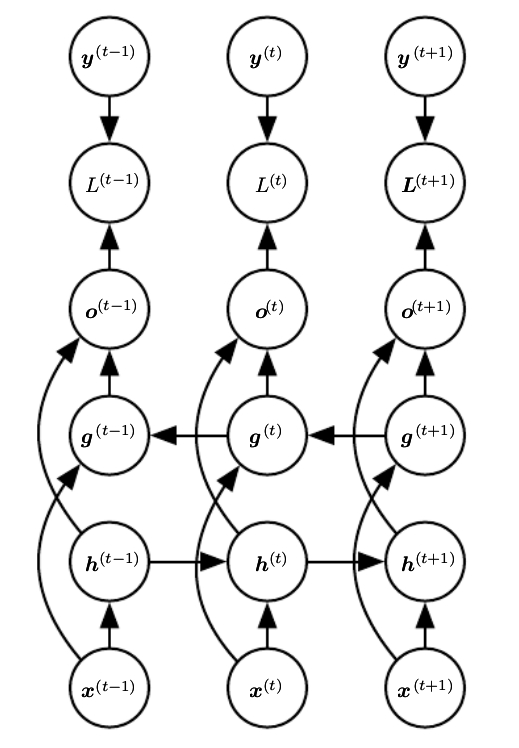
- 双向 RNN
- 总共有两个子 RNN,分别负责前向和后向的信息
- 双向 RNN 的思想可以拓展到 2D 数据(图像)上,即总共有 4 个子 RNN,分别负责上下左右的信息
- Encoder-Decoder(Seq2Seq 结构)
- encoder/reader 处理输入的序列数据,产生一个 context(通常是后一个 hidden state 的函数),decoder/writer 基于这个 context 产生 output sequence
- input 和 output sequence 的长度可以是不一致的
- 如果 context 是一个 vector,那么其实 decoder 就是一个 vector2seq,有几种方式可以实现:
- 直接将 context 作为 initial hidden state
- 将 context 作为 decoder 每个 timestep 的一个输入
- 两者结合
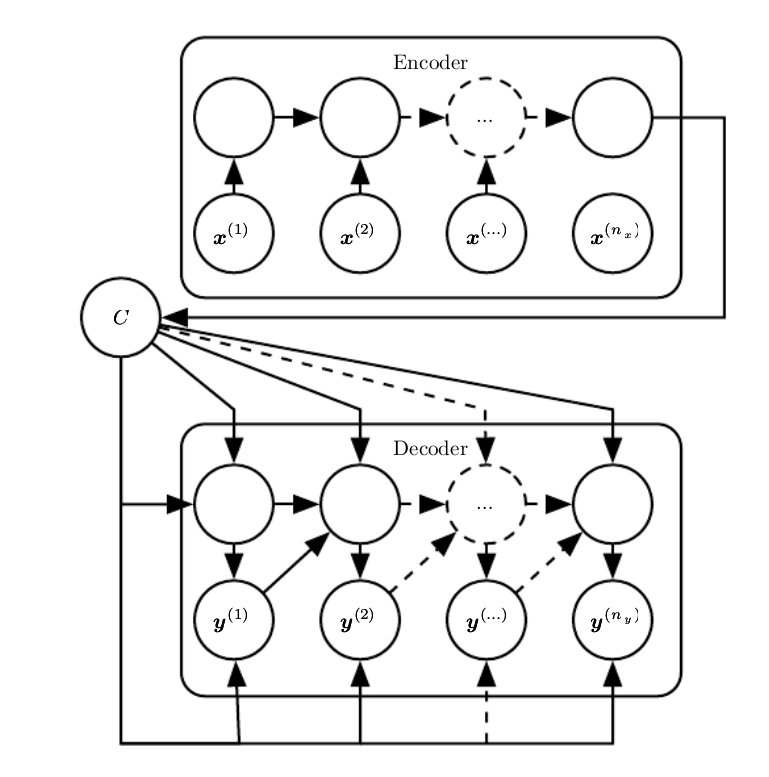
- LSTM and other Gated RNNs
- LSTM
input_gate = sigmoid( Wi * x_t + Ui * h_t-1 + bi) forget_gate = sigmoid(Wf * x_t + Uf * h_t-1 + bf) output_gate = sigmoid(Wo * x_t + Uo * h_t-1+ bo) g_t = tanh(Wg * x_t + Ug * h_t-1 + bg) # candidate input S_t = forget_gate * S_t-1 + input_gate * g_t # cell state update h_t = output_gate * tanh(S_t)LSTM 的核心思想: 维护一个 cell state,通过 forget gate 和 input gate 控制历史信息和新的 target state 之间的比重,解决了长期依赖的问题
- GRUs(update gate and reset gate)
update_gate = sigmoid(Wu * x_t + Uu * h_t-1 + bu) reset_gate = sigmoid(Wr * x_t + Ur * h_t-1 + br) g_t = tanh(Wg * x_t + reset_gate * Ug * h_t-1 + bg) h_t = (1 - update_gate) * h_t-1 + update_gate * g_t - GRU 和 LSTM 的区别?
- GRU 使用单一的 update gate 来控制遗忘历史和更新 state unit,LSTM 中用 input gate 和 forget gate 两个来控制
- GRU 在计算 target state 的时候引入了 reset_gate(非线性因素)
-
LSTM、GRU 等为什么能解决梯度弥散?
原始的 RNN 使用两个 timestep 的 hidden state 之间的关系是,h_t = sigmoid(h_t-1, x_t),这种不断“嵌套”的方式根据链式法则求解梯度时被表示成连乘形式,当梯度小于 1 时连乘会迅速逼近 0,造成梯度弥散。 LSTM、GRU 等通过对原 RNN 结构重新参数化,使得某个 timestep 的状态 state 是使用“累加”形式计算得到的,根据链式法则,求解梯度也是表示成累加的形式,从而避免了梯度弥散。
Chap11 实践方法论
- 确定优化目标(metrics)
- 考虑多个损失来源(比如垃圾邮件过滤中损失有将有用的标记为垃圾和没有将垃圾邮件标为垃圾(多个损失之间权重可能不同
- 对于类别不均匀的分类问题,采用 precision 和 recall 作为 metric
- 快速搭建一个简单的 end-to-end 模型
- 考虑实际问题,不是什么问题一开始就考虑深度模型,如果问题简单,可以先用 logistic regression 模型
- 如果选择神经网络,考虑输入和输出的结构进行选择。(FC/CNN/RNN)
- 优化方法:优先考虑的方法一个是 Momentum with a decay learning rate(线性 decay 直到一个定值,指数下降,或每次按照一个 factor decay);另一个值得考虑的是 Adam optimizer。更多深度学习的优化方法参考这里
- 激活函数一般考虑 ReLu 及相关变形(Leaky ReLu, etc.)
- Regularization (early-stop / Dropout / L2 / weight decay )
- 确定系统的瓶颈
- 观察在当前训练数据下的表现,确定是否需要更多的数据。如果没有更多数据了,只能尝试对模型进行改进。如果 finetune 后还是表现很差,考察数据本身是否有问题(太多噪声
- 如果测试集上的表现比训练集差很多,通常的解决办法就是收集更多的数据,其他的方法:减小模型大小,regulariza
- 通常可以画出数据量和 test error 的关系,观察多少数据量是合适的
- 改进模型,超参选择
- 调参的目的是使模型的容量和问题的复杂度相近。(衡量标准就是 test error)
- 几个常见参数(学习率,隐层数目,卷积核大小,zero-padding,weight decay 系数,Dropout 系数)
- 自动化探索超参(超参优化)
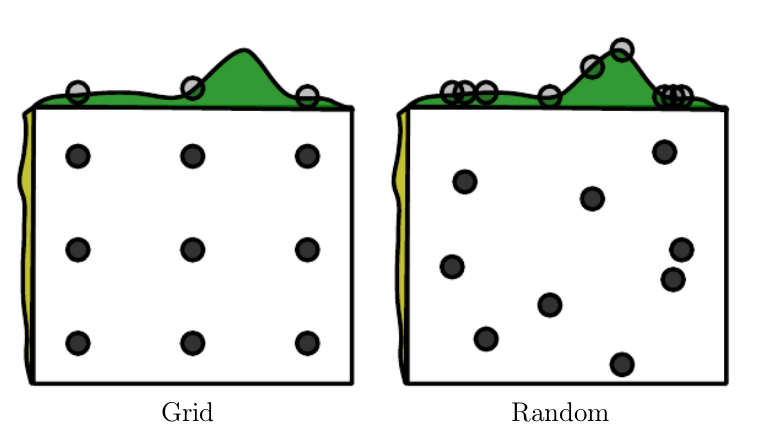
- Grid search: Grid search 对于参数每个维度设定一定的取值范围,a -> (a1,a2,a3,a4),b-> (b1,b2,b3),然后搜索所有可能的组合(a1,b1) (a1,b2)…. 返回效果最好的参数组合。(在参数维度高的时候比较低效)
- Random search 比 Random search 更优的方法,不对参数进行离散化,按照模拟的概率分布 sample。
- 贝叶斯优化 贝叶斯优化核心是拟合一个概率模型,这个概率模型 capture 参数和性能之间的关系,然后用这个模型去选择最佳的参数 每次 sample 一个样本,evaluate 得到对应的性能,更新概率模型,然后基于更新的概率模型进行下一步的采样。 优点:仅需较少的步数即可找到较优值,非常适合参数搜索这种 evaluetation 比较昂贵的问题。
- Debug 策略
- 可视化学习效果(图像标识可以打印标识区域,语音生成可以听一下生成的语音
- 根据 training error 和 test error 判断
- 检查梯度(数值计算梯度(自己实现梯度下降的时候可能出错了)
- 可视化 activations 和 gradients(tensorboard)
Chap 14 Autoencoder
TODO
Chap 15 Representation learning
学习数据的 representation(feature),使得后续的 learning task 更简单。以前是人工提取特征,现在可以使用神经网络等自动进行学习。神经网络的浅层其实就可以看作是一种 representation learning, 浅层学到一个好的 representation,最后一层相当于一个线性分类器。
- greedy layer-wise unsupervised pretraining greedy layer-wise:逐层独立进行 greedy 的预训练(每次训练一层,前面的层保持不变 unsupervised:使用 unsupervised representation learning algorithms 训练 目标是训练一个好的 weight initialization,(使参数位置处于一个相对比较好的位置,加速接下来的训练 预训练在 ReLU,Dropout,batch normalization 等优化技术出现前是常用的手段
一个例子就是 word embedding one-hot 表示的 word 他们在空间上的距离是相等的,经过 embedding 之后,词义比较相似的单词会在空间距离上比较接近。